1. The VQ Bottleneck: Why This Framework is Needed
For years, the standard way to make an LLM “see” was to use a VQ-tokenizer (like VQ-VAE) to turn patches of pixels into integers. However, the authors of UniFluid identify three “deal-breakers” with this approach:- Quantization Error (The Lossy Tax): Forcing a complex visual patch into a single integer ID from a fixed codebook is inherently lossy. Fine textures, hair, and subtle lighting are often “rounded off,” leading to blocky artifacts.
- The ‘Dead Code’ Problem: Training a discrete codebook is notoriously unstable. Often, the model only uses a small fraction of its available IDs, while the rest are “dead,” wasting the model’s capacity.
- Vocabulary Scaling: If you want a model to see more detail, you have to exponentially increase your codebook size, which makes the model computationally sluggish.
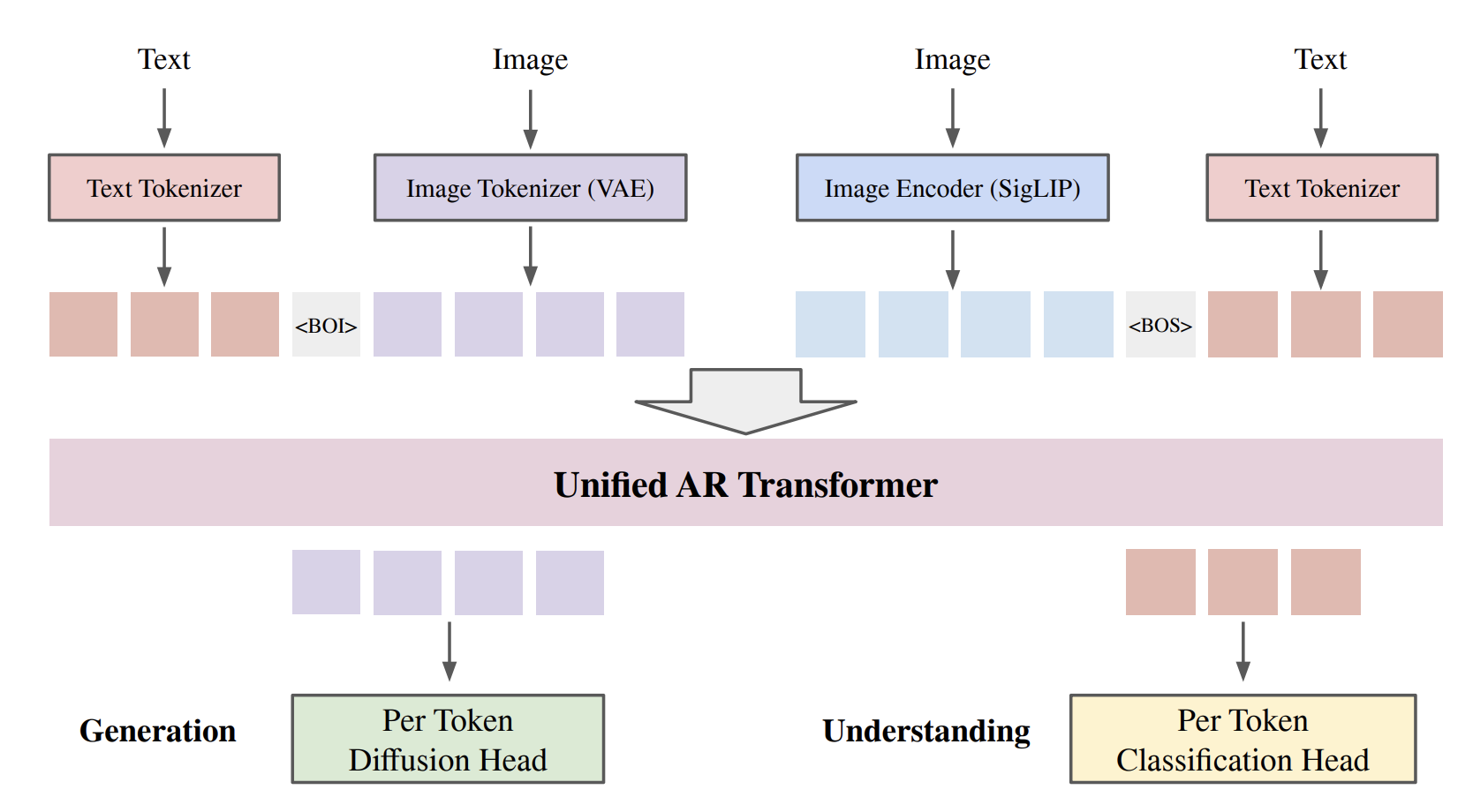
2. A Tale of Two Tasks: UniFluid vs. InternVL
In the current landscape of Multimodal LLMs, most models are specialized. A prominent example is InternVL, which has set benchmarks for multimodal Understanding (like OCR and complex VQA). However, InternVL and similar models are primarily “readers”—they are not natively designed to “write” (generate) pixels. UniFluid breaks this mold by being truly dual-purpose. It handles two distinct tasks within a single architecture:- Visual Understanding: Like InternVL, it can describe images, solve math problems on charts, and answer complex questions.
- Visual Generation: Unlike InternVL, UniFluid can natively generate high-fidelity images from scratch or edit existing ones without needing an external diffusion model.
3. SigLIP: Why It Outperforms CLIP in Scene Logic
To “read” an image (the Understanding task), UniFluid utilizes SigLIP (Sigmoid Language-Image Pre-training).- Independent Sigmoid Loss: Unlike CLIP’s softmax (which forces objects to compete for a label), SigLIP uses a Sigmoid loss. This allows the model to treat every object-text pair as an independent “Yes/No” question.
- Scene Reasoning: In a busy street, SigLIP can be 90% sure about a “car” AND 90% sure about a “pedestrian” simultaneously. This provides the LLM with a much richer, multi-object context for reasoning tasks.
4. The Generation Pipeline: SigLIP as Instruction, VAE as Target
For the Generation task, the architecture is designed to avoid the “fuzzy” output of standard autoregressive models.- The Instruction (SigLIP): The model uses the hidden states from the SigLIP encoder and the text prompt as the “instructions” for what to draw.
- The Label (Continuous VAE): Instead of trying to guess a discrete token ID, the model uses the latent values from a Continuous VAE as its ground-truth “labels.”
- The Diffusion Head: Sitting on top of the LLM is a lightweight Diffusion Head. It takes the LLM’s conceptual hidden state and denoises it to generate the exact Continuous VAE hidden state needed for the patch.
- The Decoder: These refined states are then passed to the VAE decoder to render the final pixels.
5. Random-Order Training: The Key to Visual Logic
Traditional autoregressive models generate images like an ink-jet printer: left-to-right, top-to-bottom (Raster Scan). UniFluid breaks this convention with Random-Order Training.- Global Structural Awareness: By training in a random order, the model learns that any part of the image can be a context for any other part.
- Global Coherence: This prevents the “drifting” common in AR models, where the bottom of an image doesn’t match the top. The model learns to check the “whole picture” constantly.
6. The Results: Synergy in Action
The paper’s most striking finding is the Synergy Effect. When they balanced the losses (), the 2B parameter UniFluid model actually outperformed separate models trained for only one task.| Task | Baseline (Separate) | UniFluid (Unified) |
|---|---|---|
| Generation (FID) | 7.88 | 7.20 |
| Understanding (VQA) | 65.2 | 66.8 |
Read the Paper
Source: UniFluid: Unified Autoregressive Visual Generation and Understanding with Continuous Tokens
Authors: Lijie Fan, et al. (March 2025)